2.4 시스템 서비스(System Services)
현대 시스템은 시스템 서비스의 집합체
시스템 서비스(= 시스템 유틸리티(System Utility)): 프로그램 개발과 실행에 편리한 환경 제공
- 파일 관리(File Management)
파일과 디렉터리를 생성, 삭제, 복사, 이름 변경, 인쇄, 열거 및 조작 - 상태 정보(Status Information)
날짜, 시간, 가용 메모리 크기, 가용 디스크 공간 크기, 사용자 수
성능, 로깅, 디버깅
환경 설정 정보 저장, 검색, 등록 - 파일 변경(File Modification)
파일 내용을 생성하고 편집하기 위한 Text Editor 사용
파일 내용 검색 및 변환을 위한 특수 명령어 - 프로그래밍언어 지원(Programming-Language Support)
컴파일러, 어셈블러, 디버거 및 인터프리터 제공 또는 다운로드 사용 - 프로그램 적재와 실행(Program loading and Execution)
어셈블 또는 컴파일된 프로그램을 메모리에 올리기 위한(프로그램은 메모리에 올라가야 실행된다)
절대 로더(absolute loader), 배치 가능 로더(relocatable loader), 링키지 에디터(linkage editor),
중첩 로더(overlay loader) + 디버깅 시스템 제공 - 통신(Communications)
프로세스, 사용자, 컴퓨터 시스템 사이의 가상 연결 생성 기법 제공
(e.g 메시지 전송, 웹 검색, 원격 로그인, 파일 전송 등) - 백그라운드 서비스(Background Services)
시스템이 종료될 때까지 실행될 프로세스(Known as services, subsystems, or deamons)의 작동 환경 제공
(e.g 프로세스 스케줄러, 시스템 오류 감시 및 출력 서비스, 네트워크 데몬 등)
사용자 관점에서 운영체제는 시스템 콜(system call) 보다는, 응용 프로그램과 시스템 프로그램들에 의해 결정된다
2.5 링커와 로더(Linkers and Loaders)

소스 파일을 컴파일해 재배치 가능한 오브젝트 파일(relocatable object file)로 변경
Object File Format
재배치 가능한 오브젝트 파일(Relocatable Object File):
코드(Binary Code)와 데이터를 포함한다. 다른 재배치 가능한 오브젝트 파일과 연결하여
동적 실행 파일, 공유 오브젝트 파일, 다른 재배치 가능한 오브젝트 파일 생성에 적합하다
동적 실행가능 파일(Dynamic Executable File):
실행할 준비가 된 파일. exec(2)(System call의 일종)가 프로그램의 프로세스 이미지를 어떻게 생성할지 특정한다.
일반적으로 프로세스 이미지 생성을 위해 런타임 시 공유된 목적 파일과 바인딩된다
공유된 오브젝트 파일(Shared Object File):
추가적인 링킹을 위한 코드와 데이터를 가지고 있다. 링크 편집기는 다른 재배치 가능한 오브젝트 파일과 공유된 오브젝트 파일들을 함께 처리해 다른 오브젝트 파일을 생성한다. 런타임 링커는 공유된 오브젝트 파일과 동적 실행가능 파일, 또 다른 공유된 오브젝트 파일을 결합하여 새로운 프로세스 이미지를 생성한다
재배치 가능한 오브젝트 파일은 .o의 확장자를 가진다
소스 파일을 컴파일한 뒤 만들어지며, 기계어 코드를 가진 바이너리 파일이다
링커는 이 파일을 이진 실행 파일(binary executable file)로 결합하는 역할을 한다
이때, 다른 오브젝트 파일이나 라이브러리를 결합할 수 있다
로더는 링커가 결합해 놓은 이진 실행 파일을 메모리에 적재한다(이게 로딩)
메모리에 적재가 되어야 실행 가능한 상태가 되어 CPU가 작업할 수 있게 된다
링크와 로더는 재배치를 통해 프로그램에 최종 주소를 등록하고 이 주소와 프로그램 내의 코드 및 데이터를 일치시키기 위해 조정하는 역할을 한다(이를 통해 코드가 실행될 때 라이브러리 함수를 호출하고 변수에 접근할 수 있게 된다)
=> 링크와 로더가 주소를 할당하고 조정하여 코드랑 일치시켜 주고, 코드가 함수와 변수에 접근해 제 기능을 하도록 만들어준다
* 잘못된 내용은 댓글로 알려주시면 감사하겠습니다
2.6 응용 프로그램이 운영체제마다 다른 이유(Why Applications Are Operating System Specific)
기본적으로 한 운영체제에서 컴파일된 응용 프로그램을 다른 운영체제에서 실행할 수 없다
(시스템 콜은 유사하지만, 호출 방식과 컴파일된 코드 등이 다르기 때문 아닐까?)
하지만, 우리는 다른 운영체제에서 동일한 응용 프로그램을 사용한 적이 있다
세 가지 방법
- 인터프리터 언어를 사용해 운영체제에 맞는 시스템 콜을 호출한다(e.g Python, Ruby...)
- 가상 머신을 활용한다(e.g Java의 JVM...)
- 개발자가 이진 파일 생성 표준 언어 또는 API를 사용한다(e.g POSIX...)
1, 2번은 성능 저하나 일부 기능 제한 등의 단점이 존재한다
3번은 이식에 많은 시간과 디버깅이 필요하며, 새로운 버전이 생길 때마다 수행해야 하는 단점이 있다
이런 상황에도 불구하고 저수준의 시스템(핵심 기능, 하드웨어 제어 등의 단계)에 어려움이 존재하여 크로스 플랫폼 개발이 어렵다
- 운영체제 내에 있는 이진 형식 응용 프로그램에 대한 차이
이진 형식 응용 프로그램은 헤더, 명령어 및 변수 배치 등을 명령하는데, 운영체제가 이를 사용하기 위해서는 특정 위치에 구체적 구조로 있어야 한다 - CPU는 다양한 명령어 집합을 가지며, 해당 명령어가 포함된 응용 프로그램만 올바르게 실행할 수 있다
- 운영체제는 시스템 콜을 제공하는데, 이는 운영체제마다 다르다
구조적 차이는 있지만, 도움 되는 방법도 몇 가지 있다
ELF(Executable and Linkable Format)는 UNIX, Linux 등의 시스템에 공통 표준을 제공한다(하지만 다른 하드웨어 플랫폼에서 실행될 것이라는 보장은 없다)
API는 응용 프로그램 수준이고, 아키텍처 수준에서 사용하는 ABI(Application Binary Interface)가 있다
주소 길이, 시스템 콜에 매개변수 전달 방법, 런타임 스택 구성, 시스템 라이브러리 이진 형식 및 데이터 유형 크기 등 저수준(low-level)의 세부 사항을 명시한다
하지만 ABI 또한 플랫폼 간 호환성 제공은 거의 없다(아키텍처 별로 다르기 때문인 듯)
2.7 운영체제 설계 및 구현(Operating System Design and Implementation)
2.7.1 설계 목표(Design Goals)
시스템의 목표와 명세를 정의하는 일
사용자 목적과 시스템 목적 두 가지가 있으나, 둘 다 애매하고 사람마다 다르다
따라서 유일한 해법은 없지만, 소프트웨어 공학 분야에서 개발된 일반적 원칙들이 존재한다
2.7.2 기법과 정책(Mechanisms and Policies)
기법(Mechanism)으로부터 정책을 분리하는 것은 하나의 중요한 원칙
기법: 어떤 일을 어떻게(How) 할 것인가?
정책: 무엇(What)을 할 것인가?
정책 결정은 자원 할당에 있어 중요하며, 기법이 정책과 적절하게 분리된다면
요구되는 다양한 정책을 지원할 수 있게 된다
2.7.3 구현(Implementation)
설계 다음 단계는 구현이다
고급 언어나 최소한의 시스템 구현 언어를 사용함으로써
빠른 코드 작성, 간결한 코드, 빠른 이해, 쉬운 디버그 등이 있다
또한 이식성도 좋아진다
단점으로는 속도 저하, 저장 공간을 많이 차지하는 것이지만, 오늘날에는 큰 문제가 되지 않는다
운영체제의 성능 향상은 우수한 어셈블리어 코드보다는 좋은 자료구조와 효율적인 알고리즘이다
또한 운영체제가 크긴 하지만, 그중 적은 일부만이 고성능이 중요하다
2.8 운영체제 구조(Operating System Structures)
1장에서 본 운영체제 구성요소들이 어떻게 상호 연결되고 결합되는지
2.8.1 모놀리식 구조(Monolithic Structure)
가장 간단한 구조는 구조가 없는 것
모든 기능을 단일 주소 공간에서 실행되는 단일 정적 이진 파일에 넣는다
이 모놀리식 방법은 운영체제를 설계하는 일반적 기술이다
최초의 UNIX 운영체제가 모놀리식 구조
시스템 콜 인터페이스 아래, 물리적 하드웨어 위가 모두 커널
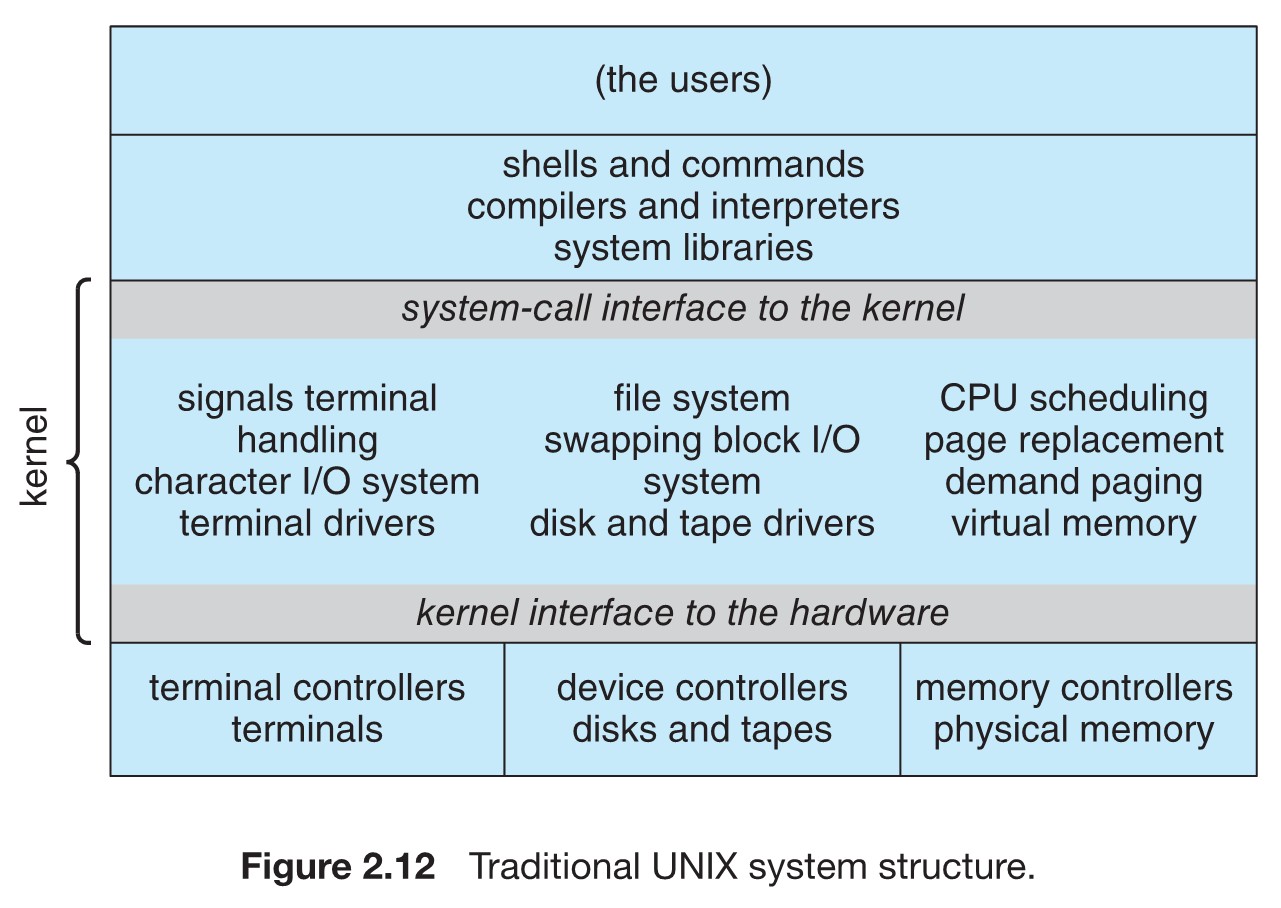
Linux 커널은 단일 주소 공간에서 커널 모드로 전부 실행되어 모놀리식 구조
그러나, 적재 가능 커널모듈(LKM, Loadable Kernel Modules) 설계도 갖추고 있다
모놀리식 커널은 단순하지만 구현 및 확장이 어렵다
안정성에도 문제가 있다
커널 하나에 다 때려 박아서 하나만 고장 나도 커널 전체가 동작하지 않을 위험이 있다
그러나 오버헤드가 거의 없고, 커널 내 통신이 빠르다
그래서 단점에도 불구하고 사용한다
모놀리식(Monolithic) 구조가 구현 및 확장이 어려운 이유?
패치하고 업데이트하려고 보니까 여기저기 연결되고 의존하고 있어 문제가 많이 생긴다
코드 제거 및 새로운 코드 작성의 어려움이 곧 유지보수를 어렵게 하고 확장성을 떨어뜨린다
물론 한 커널 내에 있기 때문에 커널 통신성이 좋아서 새로운 기능이 커널에서 작동하기 쉬운 면도 있다
하지만 일반적으로 추가할 때 많은 어려움(복잡성, 상호 연관성, 안정성, 디버깅 문제 등)이 따른다
2.8.2 계층적 접근(Layered Approach)
모놀리식은 밀접한 결합(tightly copuled)이며, 대안으로 느슨한 결합(loosely coupled) 시스템 설계가 있다
계층적 접근 방식은 운영체제를 여러 층으로 나누어 하드웨어(0층)부터 사용자 인터페이스(N층)로 이루어져 있다
계층적 접근 방식은 구현과 디버깅을 간단하게 할 수 있다
각 층은 자신의 하위층의 기능만 사용하면 된다
이로 인해 검증과 디버깅이 용이해진다(문제가 생긴 층을 찾으면 그 층이 범인이다)
상위층은 하위층이 어떻게 구현되었는지 알 필요 없다
다만 어떤 일을 하는지만 알면 된다
각 층은 데이터 구조, 연산, 하드웨어 존재를 상위 층에 숨긴다
네트워크에서 계층적 접근은 OSI 7 계층과 같이 성공적으로 사용되었다
하지만 운영체제는 사용자 요청에 대한 오버헤드 문제와
계층별 기능의 정의 문제로 인해 순수한 계층적 구조로 설계되지 못했다
2.8.3 마이크로커널(Microkernels)
마이크로커널의 주 기능: 클라이언트 프로그램과 사용자 공간에서 수행되는 서비스 사이의 통신 제공
운영체제의 확장이 쉬워진다
또한 사용자 프로세스로 수행되기 때문에 보안성과 신뢰성이 더 높다
macOS, iOS의 Darwin과 QNX가 있다
하지만 마이크로커널에선 시스템 기능 오버헤드로 인해 성능이 나빠진다
서비스 사이의 통신을 위해 메시지를 복사해야 하고, 교환을 위해 프로세스 전환이 일어날 수도 있다
이런 오버헤드의 증가가 마이크로커널 기반의 운영체제 사용을 어렵게 했다
2.8.4 모듈(Modules)
적재가능 커널 모듈(LKM, Loadable kernel modules) 기법의 사용
커널은 핵심 구성 요소만 있고, 부팅 또는 실행 중에 부가 서비스를 모듈을 통해 링크한다
커널은 핵심 서비스를 제공, 다른 서비스들은 커널이 실행되는 동안 동적으로 구현
새로운 기능을 동적으로 링크하면, 새로운 기능을 커널에 넣고 새로 컴파일할 필요를 줄일 수 있다
모듈은 계층 구조와 비슷하지만 다른 모듈을 호출할 수 있어 더 유연하다
중심 모듈은 핵심 기능만 갖고 있고, 다른 모듈을 적재하고 통신하는 방법을 안다는 점에서 마이크로커널과도 유사하다
하지만 메시지 전달 호출이 필요 없어 더 효율적이다
2.8.5 하이브리드 시스템(Hybrid Systems)
Linux는 하나의 주소 공간에 운영체제를 전부 넣어 효율적 성능을 제공하므로 모놀리식이다
그러나 모듈을 사용한다
macOS와 iOS(macOS and iOS)
Darwin은 Mach 마이크로커널 + BSD UNIX 커널로 구성된 계층화 시스템
Mach 시스템 콜(트랩)과 BSD 시스템 콜(POSIX 기능) 두 개의 시스템 콜 인터페이스를 제공
Mach
메모리 관리, CPU 스케줄링, 메시지 전달, 원격 프로시저 호출(RPC, remote procedure call)과 같은
프로세스 간 통신(IPC) 기능을 포함한 기본 운영체제 서비스 제공
Android
Java 언어로 개발하지만 ART(Android RunTime)에서 실행
Java는 JIT(Just-In-Time) 컴파일이지만 ART에서는 AOT(Ahead-Of-Time) 컴파일을 수행
AOT 컴파일은 전력 소비를 줄이면서 효율적인 응용 프로그램 실행을 가능하게 한다
Window에서 Linux를 사용할 수 있는 이유는
LXCore 및 LXSS라는 커널 서비스 덕분
그러나 항상 일대일 매치가 되는 것은 아니다
이럴 때는 기존 fork() 함수의 일부를 실행한 뒤, CreateProcess()를 호출하여 나머지 작업을 수행
(일부를 수행하고 모자란 부분은 원래 함수에서 채우기)
2.9 운영체제 빌딩과 부팅(Building and Booting an Operating System)
2.9.1 운영체제 생성(Operating System Generation)
운영체제가 없으면 다음의 옵션을 따른다
- 운영체제 소스 코드를 작성한다(이전에 작성된 소스코드 확보)
- 운영체제가 실행될 시스템의 운영체제 구성
- 운영체제를 컴파일
- 운영체제 설치
- 컴퓨터와 새 운영체제 부팅
새로 설치할 수도 있고
Virtual Box 또는 VMware와 같은 가상화 소프트웨어를 사용할 수 있다
2.9.2 시스템 부트(System Boot)
하드웨어는 어떻게 커널의 위치 또는 커널 적재 방법을 알까?
- 부트스트랩 프로그램 또는 부트 로더라는 작은 코드가 커널 위치를 찾는다
- 커널이 메모리에 적재
- 커널은 하드웨어 초기화
- 루트 파일 시스템 마운트
컴퓨터 전원을 켜면 BIOS라는 비휘발성 펌웨어 내의 소형 부트로더 실행
최신 컴퓨터는 UEFI(Unified Extensible Firmware Interface)로 대체 - BIOS보다 빠르다
GRUB은 Linux 및 UNIX를 위한 공개 소스 부트스트랩
부트 로더는 initramfs로 알려진 임시 RAM 파일 시스템을 생성
부트 로더는 하드웨어 문제 진단, 손상 파일 시스템 복구, 운영체제 재설치 등의 복구모드와
단일 사용자 모드로 부팅하는 기능을 제공
2.10 운영체제 디버깅(Operating System Debugging)
디버깅이란?
하드웨어와 소프트웨어에서 시스템의 오류를 발견하고 수정하는 행위
병목 현상(bottlenecks) 제거로 성능 향상을 하기 위한 성능 조정(performance tuning)도 디버깅에 포함된다
2.10.1 장애 분석(Failure Analysis)
프로세스 실패 시 운영체제의 대부분은 경고를 위한 오류 정보를 로그 파일에 기록
프로세스가 사용하던 메모리를 캡처한 코어 덤프(core dump)를 수행(비정상 종료된 메모리 상태를 파일에 기록)하고 분석을 위해 파일로 저장한다
커널 장애는 크래시(crash)라고 부른다
크래시는 크래시 덤프(crash dump)에 저장
2.10.2 성능 관찰 및 조정(Performance Monitoring and Tuning)
시스템 동작을 측정하고 표시할 수 있는 두 가지 방법(도구)
카운터(Counter)
호출된 시스템 콜 횟수 또는 네트워크 장치나 디스크 수행 작업 수 같은 시스템 활동을 추적
(Linux 예시 - 프로세스(ps, top), 시스템 전체(vmstat, netstat, iostat)
EC2나 도커를 활용할 때 리눅스 커널로 자주 쳤던 명령어다
Linux Counter 기반 도구는 대부분 /proc 파일 시스템에서 통계를 읽어온다
Windows에서는 작업 관리자를 제공한다
2.10.3 추적(Trace)
카운터 기반은 커널에서 유지 관리하는 현재 값에 대해 간단히 보여주지만
추적은 시스템 콜과 같은 특정 이벤트에 대한 데이터를 수집한다
Linux 예시 - 프로세스(strace, gdb), 시스템 전체(perf, tcpdump)
2.10.4 BCC(BPF Compiler Collection)
이런 계측 도구는 성능에 영향을 최소로 하면서, 시스템 안정성을 해치지 않아야 한다
(이상적인 것은 사용할 때는 최소로, 사용 안 할 때는 영향 0)
BCC는 요구 조건을 만족하면서 동적이고 안전하며 낮은 영향력을 미치는 디버깅 환경을 제공한다
BCC는 eBPF(extended Berkeley Packet Filter) 도구에 대한 FE 인터페이스
Python으로 작성된 FE 인터페이스를 제공한다
나머지는 강의를 통해 추가 학습해 이해해야겠다
다음 글에 내 정리와 문제 풀이를 작성할 예정이다
혹시 잘못된 내용은 댓글로 의견 주시면 감사하겠습니다
참고
https://os.ecci.ucr.ac.cr/slides/Abraham-Silberschatz-Operating-System-Concepts-10th-2018.pdf
https://docs.oracle.com/cd/E23824_01/html/819-0690/chapter6-46512.html
'CS > Operating System' 카테고리의 다른 글
| 운영체제 구조(Operating System Structures) - 3 (0) | 2024.06.25 |
|---|---|
| 운영체제 구조(Operating System Structures) - 1 (1) | 2024.06.02 |
| 운영체제(Operating System)란? - 2 (1) | 2024.05.29 |
| 운영체제(Operating System)란? - 1 (0) | 2024.05.29 |

